

This article is based on a presentation given by Sarwat Fatima, Principal Data Engineer at Biome Analytics, at the Data Pipeline Automation Summit 2023. With more than eight years of experience in diverse industries, Sarwat has spent the last four building over 20 data pipelines in both Python and PySpark with hundreds of lines of code. The information presented here is a summary of her insights and experiences.
Reading not your thing? Dive right into Sarwat’s full presentation at the Data Pipeline Automation Summit 2023.
Table of Contents
Data is the lifeblood of the healthcare industry. Without it, we wouldn’t be able to make informed decisions, predict outcomes, or innovate. But as data engineering professionals, we’re well aware that handling this data is no easy task.
The question then arises: how can we efficiently manage and process this ever-growing mountain of data to uncover the value it holds? The answer lies in building efficient healthcare data pipelines. But what does that journey look like? Let’s dive into Biome’s journey of building data pipelines using Ascend to find out.
Healthcare and Its Economic Impact
Did you know that the United States is an outlier when it comes to healthcare spending compared to other high-income countries in the world? The U.S. healthcare sector’s expenditure was 18.3% of the total GDP in 2021, amounting to $4.3 trillion. By 2030, this figure is projected to rise to 19.6% of the total GDP.
Why does this matter? There are three significant reasons:
- A healthier workforce means a more productive workforce, positively impacting the nation’s economic health.
- The cost of healthcare is built into the price of every American product and service. A decrease in healthcare costs could enhance competitiveness in the global market.
- According to the Commonwealth Fund, U.S. health expenditures are more than twice the average of other countries, and about three to four times more than countries like South Korea, New Zealand, and Japan.
How Does Biome Reduce Cardiovascular Care Costs?
Biome Analytics develops performance improvement solutions for cardiovascular centers. Our main objective is to help practitioners understand their clinical and financial operations and recommend opportunities for improvement in how procedures are prescribed and performed at the point of service.
Guiding hospitals to assign better-tailored treatments and claim the right costs from insurance providers also reduces the risks of forgone revenue due to denied claims. Better treatments also lead to better patient outcomes and improved rankings in cardiovascular clinical programs.
By working with many hospital systems across the US, Biome:
- Has helped hospitals reduce bleeding events by 69%
- Has decreased outpatient length of stay by 50%
- Has reduced unnecessary variation in healthcare by 35%
- Has improved performance to be 90% better compared to other cardiovascular services
- Has increased the contribution margin of hospitals by $6 million

Healthcare Data Pipeline Evolution: From mySQL to Spark
These valuable impacts on the industry and on human lives requires processing vast amounts of data. Biome Analytics receives two types of datasets from hospitals: financial and clinical datasets.
- The clinical dataset consists of all characteristics, treatments, and outcomes of cardiac disease patients.
- The financial dataset includes cost-related information for each procedure, service, or diagnosis.
At this point, the datasets include over 2 billion records, comprised of 1.5 billion financial records and 8.3 million clinical records. Due to HIPAA compliance, Biome Analytics maintains over 70 separate groups of data pipelines, one for each client. Typically, each hospital requires two to six data pipelines, which need to be executed monthly.
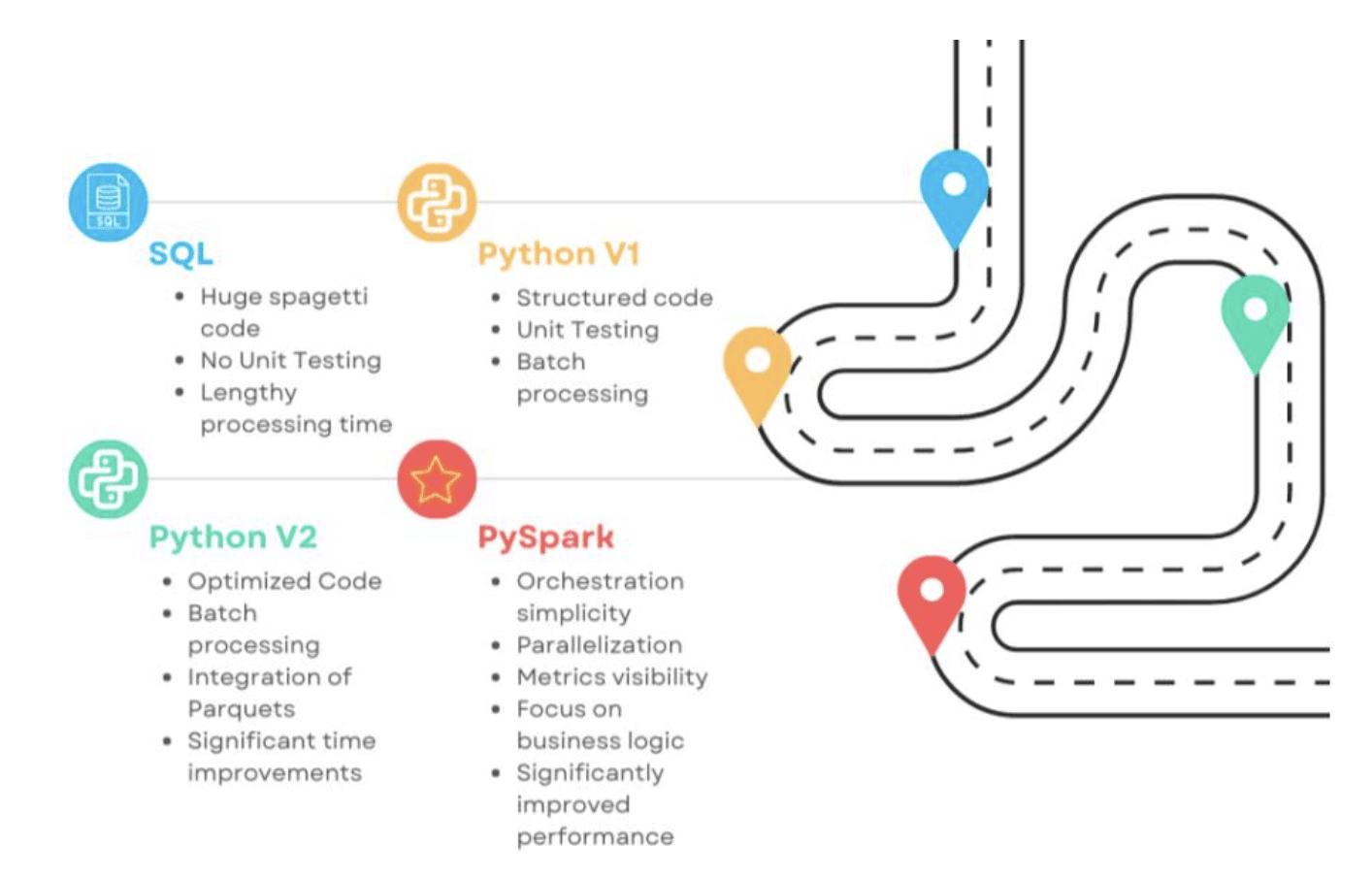
The SQL Era
In the early days of our data journey, pipelines were crafted in many mySQL databases. Every data mapping configuration found its home in mySQL tables, with enormous SQL scripts designated for each admin, financial, and clinical dataset. The entirety of the code resided in one colossal repository, a monolith without a solid structure to ensure bug-free production code. It served us well when Biome got started, but as the data volume surged, the execution time became unbearable.
Infrastructure Overhaul and Transition to Python
Realizing that this behemoth was growing too sluggish, we decided to pivot to Python. In conjunction with this migration, we also revamped our infrastructure. We bid adieu to SVN and embraced GitLab as our primary version control tool. We set up our own PyPI server for internal packages, and an Azure container registry became the new home for our image-based data.
As we restructured SQL code into Python, we segregated it into distinct repositories for each financial and clinical dataset. During this phase, we discovered that many common transformations could be housed in a single repository. This unifying repository then served as a package, which all other data pipelines could utilize, fostering reusability and consistency.
The first iteration of our Python data pipeline involved batch processing, where each batch was extracted, processed, and loaded back into the table, incurring substantial network costs. To mitigate this, in Python v2, we replaced the intermediate processing batches with Parquet storage and loaded the table once into the database, rather than after each batch. This strategy dramatically reduced processing time and network costs.
Big Data with Spark and Ascend
Yet, as data volumes continued to swell, processing time still crept upwards. Our answer to this challenge lay in big data processing. We migrated our pipelines to Spark using Ascend, which allowed us to shift our focus away from maintaining complex orchestration and scheduling and toward improving the value of the business logic.
Biome had previously attempted a popular open-source solution for orchestration, metrics, and scheduling. However, the management overhead turned out to be daunting, and the benefits were murky at best. It seemed we were creating more problems than solutions.
In contrast, Ascend provides a robust framework out of the box that addressed our needs, enabling us to take on the rapidly increasing data volumes from our customers while reducing the time spent on orchestration and scheduling.
Leveraging Ascend for Healthcare Data Pipelines
So let’s discuss how we’re using Ascend to automate our data pipelines.
Biome Analytics employs two methods of development on Ascend: UI-first and SDK-first. UI-first is used for pipelines that are executed once, while SDK-first is used for pipelines that are executed across multiple clients and with multiple clinical datasets.
Development of Ascend dataflows comprises two dimensions:
- Leveraging the CI/CD pipeline
- Using design patterns and the Ascend SDK to enhance dataflow functionality
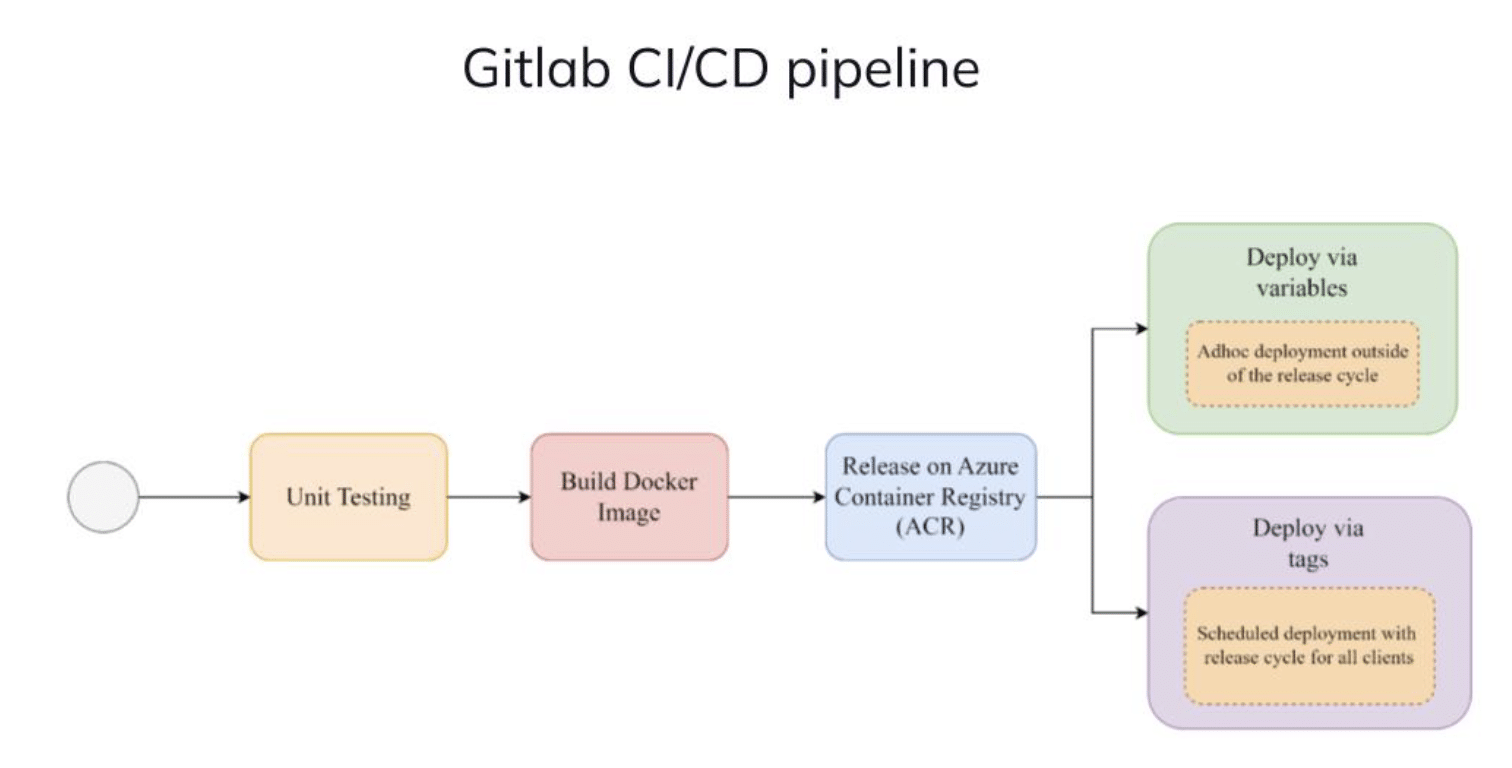
In the CI/CD pipeline, the initial stage involves static code testing and unit testing. The next stage includes building a Docker image based on data mapping configurations and some internal packages. The Docker image is then published on an Azure container registry for use on Ascend.
Dataflow Deployment via Variables and Tags
In our pipeline deployment stage, we essentially have two methods: one is via variables, and the other is via tags.
- Variable-Based Deployment: This method is used for ad hoc deployments of data flows, such as when we need to run a data flow on a specific date without refreshing data. This ad hoc data flow dumps data into a staging database with a date identifier. This method is primarily used for debugging or when it’s necessary to preserve a specific version of a dataflow for later.
- Tag-Based Deployment: Our tag-based deployment follows our bi-weekly sprint release cycle. We tag any development done during the sprint and update the data flow with the updated code.
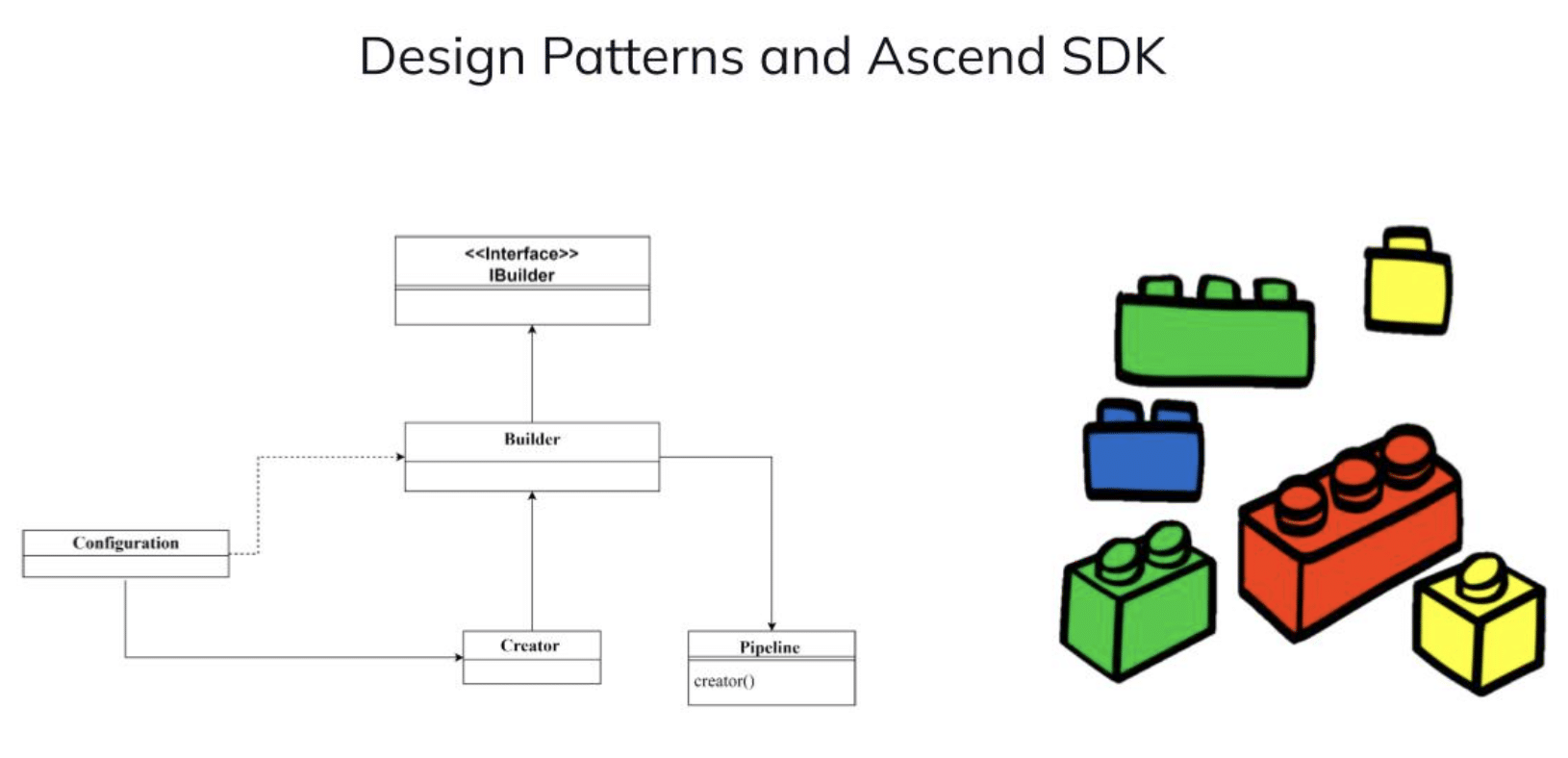
Design Patterns and Ascend SDK
We think of Ascend as a Lego set where various pieces can be arranged to create a complete dataflow. This provides flexibility for component swapping based on different requirements. We chose to use the builder design pattern, which aligns well with how Ascend works.
The pipelines are automatically deployed by our GitLab CI/CD pipeline. Adopting this design pattern has several advantages:
- Code Reusability: With multiple data pipelines, we can separate the Ascend SDK code and use it as common code instead of repeating it in each repository. This approach also makes it easier to handle significant updates from Ascend to their SDK code.
- Focus on Business Logic: As we migrated several data pipelines from Python to PySpark, this design allowed us to concentrate more on the business logic and PySpark, rather than having to write lots of orchestration code.
- Improved Engineering Productivity: Ascend SDK offers many advanced features, like dynamically creating connections and removing previous dataflows, that are highly useful for automating our dataflows.
Best Practices and Lessons Learn
In our journey of building data pipelines, we’ve gathered some best practices and lessons to share here today, that we believe can streamline your own data pipeline project:
- Understand your migration purpose: You need to translate your business requirements into technical data requirements while avoiding orchestration details. For us, the business requirement of expanding our client base translated into the technical requirements of speed and modularity.
- Design patterns are crucial: The real value lies in combining your software engineering skills with the capabilities of the tools at your disposal to build effective healthcare data pipelines.
- Create a generic CI/CD pipeline: It enforces important software development habits among your engineers. For instance, it was crucial for us to ensure that each code repository had unit tests.
- Unit testing is non-negotiable: This ensures the business logic is working as expected and there are no errors or bugs in the code. It also serves as an important documentation tool.
- Analyze data types and sparsity: This is especially vital if the data you use comes from another team. Understanding the nature of the data you are using helps you design efficient processing steps in your data pipelines.
- Consider Automation: Automate as much as possible. From CI/CD pipelines to data transformation and loading, automation reduces manual errors and boosts efficiency.
Here are some tips specific to working with Ascend:
- Choose one primary path for development: either UI development or SDK development.
- If using data feeds from different dataflows, house them in one single data service.
- Prefer using data feeds or parquet storage instead of separate staging databases.
- Always refresh read connectors right after deploying a dataflow via SDK.
- Use Ascend SDK to create dynamic read connectors for ad hoc deployments.
- Properly name your dataflows and avoid using the keyword “Ascend” in usernames and connections.
- Delete unused connections or previous dataflows if no longer required.
- Split transform components if transformations significantly change the data schema.
Future Outlook
In the vast and complex world of data, building and managing scalable healthcare data pipelines is an imperative skill for all data engineering professionals. With tools like Ascend and strategies like the builder design pattern, we can navigate this challenging terrain with far more efficiency and agility than before.
Our plans for the future include further scaling and optimization of our data pipelines. We’re also looking to integrate an event-driven architecture within Ascend, and move towards more scalable options like Azure SQL for downstream analytics, reducing our dependency on traditional relational databases.
Remember, the data we manage and the pipelines we build are not just about moving and storing bytes. It’s about harnessing the power of data to make better decisions and drive innovation, especially in critical sectors like healthcare. Our journey with Ascend has taught us that with the right tools and approaches, we can indeed turn our data challenges into opportunities.
Additional Reading and Resources


