

Every business leader’s dream is to have real-time data at their fingertips. With it, they could discover invaluable insights, pivot in real-time, and connect their work to direct revenue impact.
But they’re living in what is essentially the opposite of their fantasy. With the monolithic architectures most organizations have today, business users are stuck, constantly waiting for new data pipelines to be built or amended based on their requests.
Data engineers aren’t huge fans of this paradigm either. Only a select few people in the company know how the architecture works, which is a huge bottleneck to everyone’s productivity. And the team backlog grows longer and more unmanageable with each passing day.
The possible answers? Data mesh and data fabric.
Although both promise to make leaders’ dreams a reality, the two strategies are not the same. In this article, we’ll explain what data mesh and data fabric are and outline the key differences that can help you implement the approach that works best for your company.
What is a Data Mesh?
Data mesh is a platform architecture that decentralizes and democratizes an organization’s data by organizing it into clearly defined domains.
Each domain corresponds to a specified business area, and subject matter experts (SMEs) define how that data should be structured and used across the organization. Within each domain, data is curated into shareable data products. These products are defined and maintained by the SMEs of the domain and are made available to others throughout the business as a dependable service.
Data products are easily searchable and shareable among business units, allowing any stakeholder to use them as-is or combine them with products from other domains to create more sophisticated analytics, models, and customer-facing solutions.
The overarching philosophy of a data mesh is that it’s designed with data products in mind. Because customers and consumers can see the data that’s available to them, they can more easily brainstorm new data products. Data mesh’s distributed nature helps data engineering teams become more agile, connecting data product building blocks that already exist to form other data products.
In other words, the product one person builds might have inputs from another product. They can build on each other’s work. As long as everyone manages their products and makes sure they don’t break, the entire system stays healthy.
The data engineering team would deliver the first iteration of these data products, the business stakeholders send in their feedback, and engineers make adjustments until the product is optimized.
In theory, the ROI of a data mesh is threefold:
- Higher data product velocity via a distributed, predefined architecture
- Higher data product reuse because they are discoverable, shareable, and trustworthy
- Greater collaboration and scalability
Of course, there are a few downsides to this method as well:
- SMEs must commit to contributing to domain and data product creation.
- Data migration to a data mesh can be extremely challenging, considering the number of legacy systems and tech debt in the average tech stack.
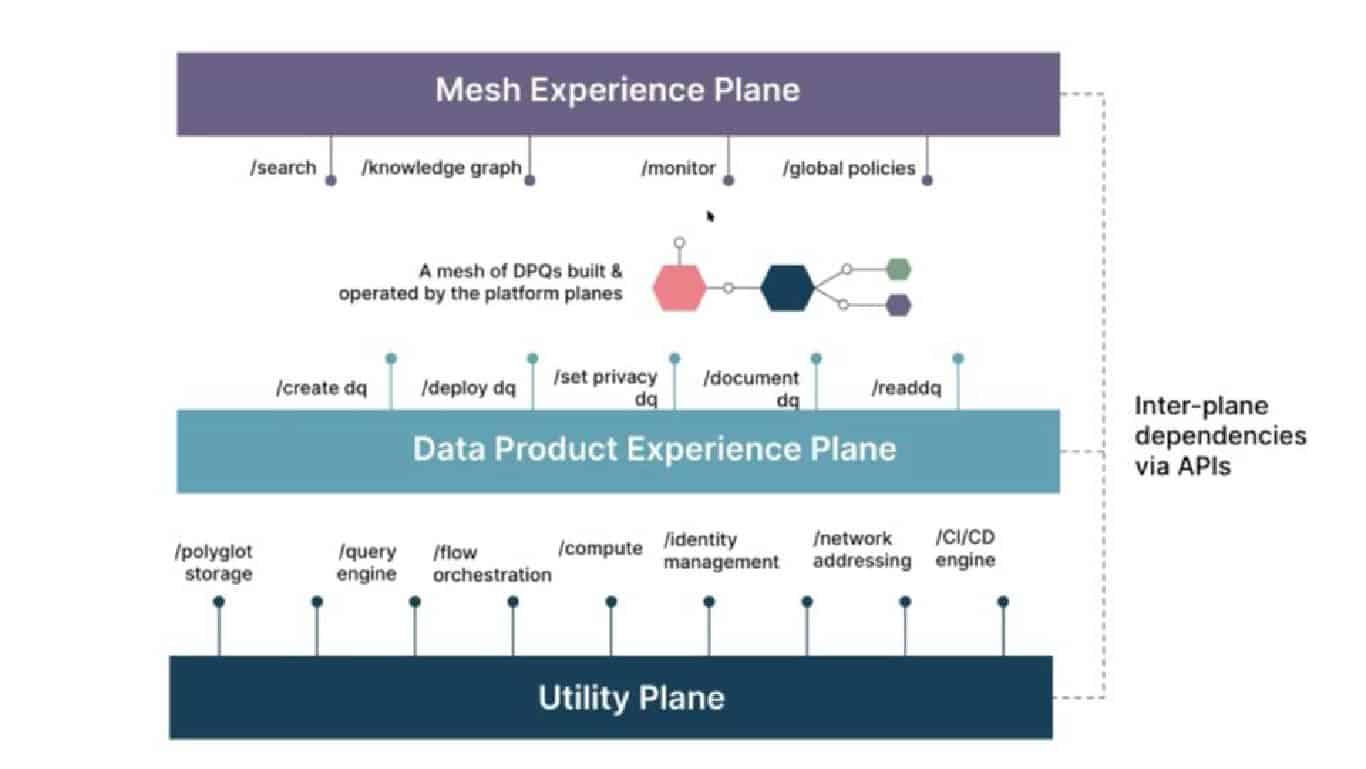
What is a Data Fabric?
Data fabric is a centralized platform architecture originating from a curated metadata layer that sits on top of an organization’s data infrastructure. Users derive meaningful business insights by querying the metadata catalog, which pulls specific data from disparate data lakes, warehouses, and lakehouses according to preconfigured data governance standards, sometimes with the help of an AI model.
Every time a new data source is added, the metadata layer is updated to define how and when that data should be used. In that way, data fabric becomes self-service — anyone can query the metadata at any time and know that the data they want is coming from the right place and has the right syntax.
With a data fabric architecture, product teams wanting to construct a customer shipment profile would query customer data, order data, and shipment data and join them together themselves. This puts less onus on the data engineering team and gives the product team the power to create their customer shipment profile the way they want to on their own time.
So, in theory, data fabric generates ROI by:
- Giving users autonomy. Data engineers trust users to understand the metadata and construct their own reports or other data products.
- Increasing speed. Anyone can query the metadata any time anywhere to get the information they need.
But there are some clear cons to a data fabric:
- Establishing and maintaining governance standards for the entire metadata layer is difficult and time-consuming.
- Different users can come up with different answers to the same question depending on how they queried the metadata.
- AI models often used to prepackage data need to be tuned and updated frequently.

Data Mesh vs. Data Fabric: Understanding the Differences
Data mesh and data fabric are at the forefront of conversations because of their potential to revolutionize the way organizations structure and use their data.
Although data mesh and data fabric share the same purpose, and theoretically have a similar ROI, they go about solving the problem of monolithic architectures in very different ways.
Data mesh is a more organization-focused approach. Companies that implement a data mesh realize that data engineering teams need the help of internal subject matter experts to define domains. Each internal stakeholder knows their side of the business inside and out. And by working closely with engineering, they can ensure that domains have the correct data in the correct format to create useful data products.
On the other hand, data fabric takes a more top-down approach, creating a broad metadata catalog atop an existing foundation. Data engineers build rules into this catalog so that when users query it, it pulls the right data from the right data lake or data warehouse (sometimes with the help of AI).
To help you make an informed decision about what methodology is right for your organization, let’s dive into the differences between the two approaches on a more detailed level.
- Data Mesh
- Data Fabric
| Data Mesh | Data Fabric | |
$3999 /year | $3999 /year | |
| Foundational Principle | Data as a product | Active metadata layer |
| Organizational Pattern | Decentralized | Centralized |
| Data Sharing | Facilitated by process | Facilitated by technology |
| Architectural Patterns | Involves both technical and business architecture changes | Requires a cataloging and semantic layer over existing architecture |
| Data Governance | Federated across each business domain | Centralized over organization's entire dataset | Buy Now | Buy Now |
Product Approach vs. Ad Hoc Approach
One of the major differences between data mesh and data fabric is the fact that data mesh thinks of data sets as a product. In a data mesh, domains are created based on internal customer input and optimized based on user feedback. This loop — similar to the one created in agile product management — drives further adoption of the data mesh.
In a data mesh, there is a supply chain to manage (raw data sources), a set of actions that create the product (collection and transformation of data), and a set of downstream consumers who need to be satisfied with the end result. Data Product Managers research what their internal customers need from each dataset and make sure it continues to meet their expectations over time.
Data fabric is far more ad hoc. Casting a net over all of the company’s existing data assets means less work moving data back and forth between different systems. With the metadata layer in place, customers can request the data they want at any time to fit their use cases. With predefined rules for consumption, the system locates the corresponding data in origin systems. In this model, there is no feedback loop because a preconfigured set informs the extraction.
Decentralized vs. Centralized
Data mesh is inherently decentralized: discoverability and sharability are two of its key attributes. Finance domains are separate from customer domains which are separate from shipment domains. And standardization is baked into each domain based on guidance from the business users who have been using that data in their day-to-day work. To make their ideal data product, stakeholders can select from the existing data product library or submit a request to build a new data product.
A data fabric architecture creates a centralized view of all data from disparate systems in one place: a data catalog. This centralized structure allows users to compose their own reports or datasets straight from the metadata layer.
Sharing
Sharing is a core assumption of data mesh — the whole concept is to empower business users with the data they need to do their jobs better. And to do that, data domains need to be both approachable and usable. If business users cannot find, consume, and intelligently combine data domains, you’re right back to a monolithic architecture.
Sharing is a component of data fabric as well, but it’s much more technical and happens behind the scenes. When consumers want to use data in the metadata catalog, the system automatically extracts and assembles data for them according to a predetermined, typically AI-driven, model. They aren’t picking and choosing datasets for their analysis.
Architectural patterns
As we hinted above, data mesh involves both technical and business architecture changes. Business stakeholders need to be involved in determining the correct data domains according to their objectives. Each data set within that domain must be considered a product and be assigned a product owner. That product owner must coordinate the resources of a data team dedicated to the domain and deliver continuous value for stakeholders.
On a technology level, each data domain must be equipped by IT with a self-service data infrastructure. More importantly, this infrastructure must be sufficiently isolated from the other domains. This ensures that mistakes made in one domain don’t take down the entire mesh. These architecture changes are a dramatic change for many organizations accustomed to centralized data infrastructures and data engineering teams.
The data fabric approach is more compatible with current centralized teams and infrastructure. Because it primarily relies on technology to stitch disparate data silos together, it can be applied to a wide variety of existing environments. The primary component of a data fabric is a metadata store that begins by collecting passive metadata and later active metadata that forms a complete picture of how the data is actually used in the organization. Data fabrics often contain a cataloging layer as well as a semantic layer, allowing for dataset exploration with natural language rather than code.
Data Governance
In a data mesh architecture, data governance is contained within each domain. When data products are created, data engineers work with an SME to define format, validity, and the proper keys for joining with other datasets.
In this way, data governance is restricted to a smaller group, which translates to closer collaboration between the builders and the users of data. At the same time, it helps maintain data quality — requirements come straight from the internal source — and it holds stakeholders accountable for data stewardship.
A data fabric architecture requires data governance across all of an organization’s data. For instance, say a user wants to explore the correlation between orders and browser history. Upon closer examination, you may realize the same customer appears four times in the customer dataset. One row has a misspelled last name, one has a slightly different phone number, another is missing the unit from the customer’s address, and the last has the “correct” information.
When building the data catalog, that “correct” version needs to be defined as the source of truth to ensure proper joining with the browser history dataset. And that’s just one small example. As data catalogs grow in volume and complexity, maintaining this level of governance can be a challenge.
Build Your Ideal Infrastructure
Data mesh and data fabric tackle the same problem every data engineering team faces today: monolithic architectures. And while they have their similarities, understanding the differences in their approach, governance, sharing, and implementation is critical in determining which architecture is better suited to propel your organization forward.
But know that building your own data mesh or data fabric from scratch comes with inherent risk — even hundreds of hours and thousands of dollars in investment can’t guarantee success. To be successful, you not only need expert resources with a solid understanding of your business, you also need executive and stakeholder buy-in, and the time to put it all together and extensively test it.
Buying a data pipeline automation platform with live data sharing can greatly accelerate the process. Learn how Ascend can put you on the road to a non-monolithic architecture by scheduling a demo with one of Ascend’s experts.
Additional Reading and Resources


