

In the fast-evolving landscape of cloud data solutions, Snowflake has consistently been at the forefront of innovation, offering enterprises sophisticated tools to optimize their data management. The introduction of Snowflake Snowpark is yet another leap forward, transforming data warehousing and revolutionizing the way customers engage with this platform.
In this article, we’ll explore what Snowflake Snowpark is, the unique functionalities it brings to the table, why it is a game-changer for developers, and how to leverage its capabilities for more streamlined and efficient data processing.
What Is Snowflake Snowpark?
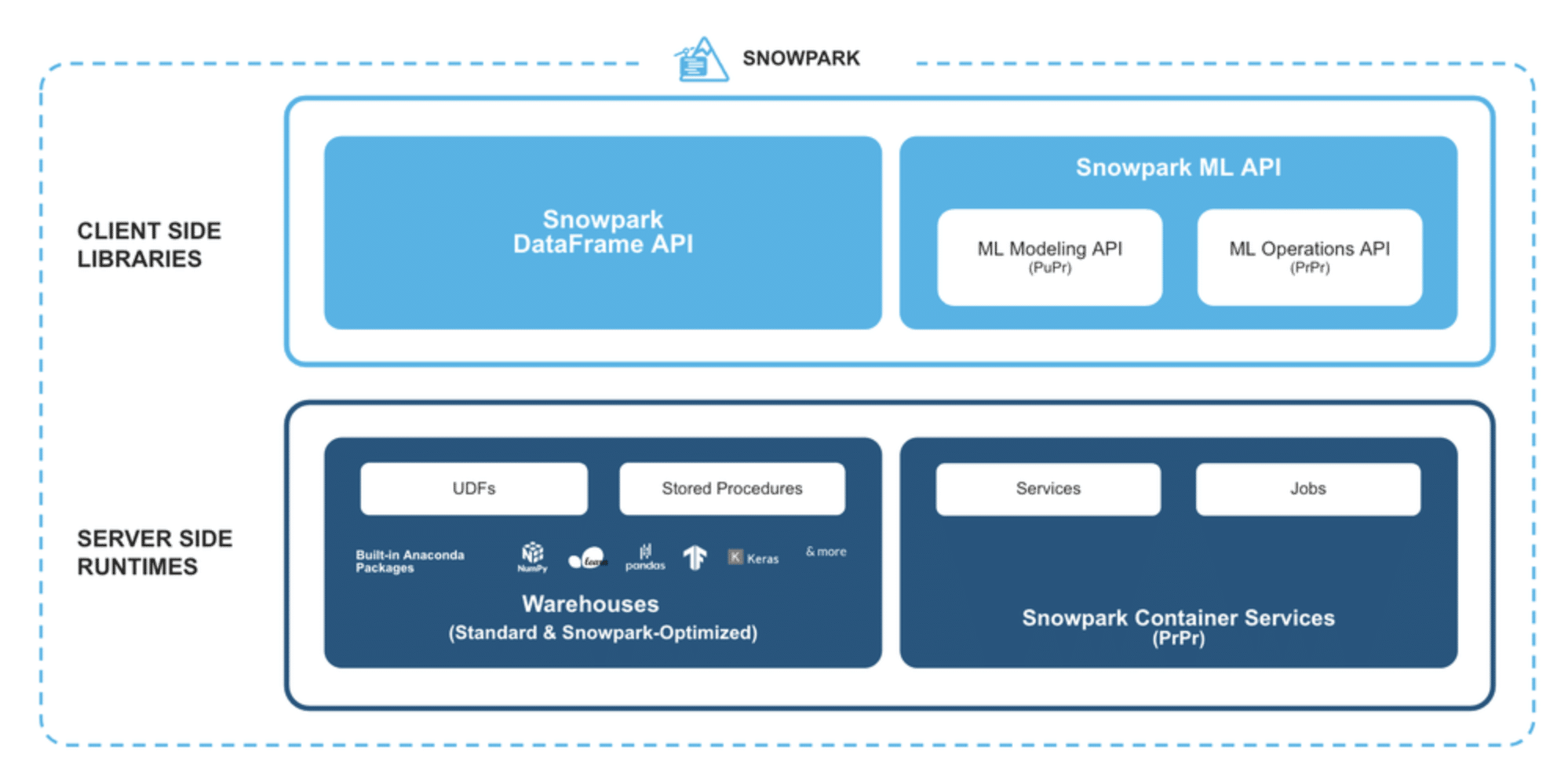
Snowpark is a library equipped with an API that developers can use for querying and processing data within the Snowflake Data Cloud. Snowpark’s key benefit is its ability to support coding in languages other than SQL—such as Scala, Java, and Python—without moving data out of Snowflake and, therefore, take full advantage of its powerful capabilities through code.
In its early days, Snowflake operated as a pure SQL-based engine, requiring external data extraction for processing in other languages. But Snowpark has catalyzed a significant paradigm shift. Customers can now process their native code inside Snowflake, essentially bringing the compute to the data. This new architecture design eliminates the need for specific places for specific data types and workloads.
Read More: How to Use Snowpark in Two Steps
Snowpark Unique Functionalities
Snowflake Snowpark introduces a plethora of distinctive features, each meticulously designed to enhance data processing, management, and operations. The details presented in this section are sourced directly from Snowflake:
Libraries
- DataFrame API: Craft queries and data transformations using the intuitive DataFrame structure. This not only streamlines data management but also ensures that processing is fully harnessed by Snowflake’s elastic processing engine, amplifying both performance and scalability.
- Snowpark ML API for Modeling: Experience the seamless scaling out of feature engineering and a simplified approach to Machine Learning (ML) training execution directly within Snowflake’s ecosystem.
- Snowpark ML API for Operations: The Snowpark Model Registry provides organizations with a centralized ML model repository, inherently designed to boost and scale MLOps, ensuring smooth operations and collaboration.
Runtimes
- User-Defined Functions (UDFs): Go beyond traditional boundaries by executing custom code written in Python, Java, or Scala directly inside Snowflake. Whether it’s intricate business logic or finely-tuned machine learning models, Snowpark’s UDFs coupled with the embedded Anaconda repository make accessing open-source libraries a breeze.
- Stored Procedures: Streamline and orchestrate DataFrame operations. With Snowpark, you can operationalize custom code, ensuring it runs both at your desired schedule and at a scale tailored to your needs.
- Snowpark Container Services: A cutting-edge feature that allows users to register, deploy, and execute container images within a Snowflake-managed infrastructure, ensuring smooth integrations and runtime operations.
Why Does Snowflake Snowpark Matter?
SQL, as a declarative language, offers a broad audience the power to query data. However, the intricate logic behind large applications and pipelines can prove convoluted when relegated to SQL alone. More often than not, such complex issues are more intuitively tackled using robust programming languages like Python, Scala, or Java, underpinned by solid software engineering principles.
Moreover, Snowpark enables developers to harness Snowflake’s computational prowess, promoting the ethos of taking the code to the data, rather than exporting data to alternate environments where large-scale data processing might be sub-optimal. The sheer versatility of Snowpark brings forth myriad advantages:
- Custom Software Development: Snowpark’s API facilitates the crafting of custom applications underpinned by intricate logic.
- Upholding DevOps and Engineering Standards: With Snowpark, developers can architect applications that are both reliable and deployable, backed by unit tests and CI/CD pipelines tailored for Snowflake.
- Leveraging Open-Source Libraries: With the extensibility of Python, Java, and Scala, Snowpark permits developers to execute these open-source libraries on Snowflake, facilitating scalable data processing both within and external to the platform.
- Latency in Distributing Resources: Traditional systems often necessitate a preparatory period, sometimes stretching up to 10 minutes, before code execution. Snowpark efficiently counters this by leveraging Snowflake’s virtual warehouses that are primed for immediate access.
- Efficient Coding Over Large Datasets: Snowpark alleviates the learning curve by providing a unified layer to access data, supplemented by the DataFrame API, mitigating direct file access challenges.
- Managing Partitions and Resolving Garbage Collection Issues: Managing partitions and navigating garbage collection often require deeper insights into data distribution and computational processes. Snowpark streamlines this process, maintaining consistent data manipulation methods once foundational skills are honed.
Better Together: Snowflake Snowpark and Ascend
The combination of Snowflake and Ascend has resulted in an integrated, high-performance platform for automating data processing workflows, regardless of scale or complexity. When you use native Snowpark within the full Ascend automation context, the resulting transformations are seamlessly orchestrated by Ascend, which assures that your Snowflake-based data pipelines benefit from ingestion and validation, guaranteed sequencing and lineage, deep job monitoring, and powerful pause/resume functions that save headaches, time, and money.
- Elimination of Non-Value Activities: Both Snowflake and Ascend are designed with a similar philosophy of eliminating non-value activities, enabling users to focus on their core business logic and making their data more usable. Tasks like managing DDLs, creating tables, breaking changes in data types, and unnecessary performance tuning, which don’t add value to the organization, are automatically handled by Ascend.
- Seamless Data Management: Ascend complements Snowflake by offering seamless data management and a smooth transition between SQL and other languages like Python. This is crucial for organizations that use both SQL and Python for data processing and analysis.
- Performance Boost: Snowpark allows processing directly within Snowflake, which significantly reduces data movement and improves performance. When a data operation that was previously handled by Spark is converted to Snowpark, the execution speed can increase dramatically, as seen in the mentioned case study.
- Automated Data Partitioning: Ascend enhances Snowflake’s capabilities with its unique handling of data partitions. This becomes particularly crucial for managing very large data sets, enabling efficient data processing.
- Flexibility: Ascend provides flexibility in the use of Snowpark. If a specific operation cannot be performed using Snowpark, it can be handled using PySpark in Ascend. This ensures that users can always use the most suitable tool for the task at hand.
- Future-Proofing: Ascend’s commitment to accommodate future Snowflake features, such as GPU support and hosting of Streamlit-built applications, ensures a consistent, innovative, and integrated environment for users. This paves the way for new interactions and capabilities.
- Data Governance: With Ascend, users can track various metrics such as byte consumption and record counts, as well as build lineage through the entire process, including Python and SQL. This enhances data governance and aids in decision-making.
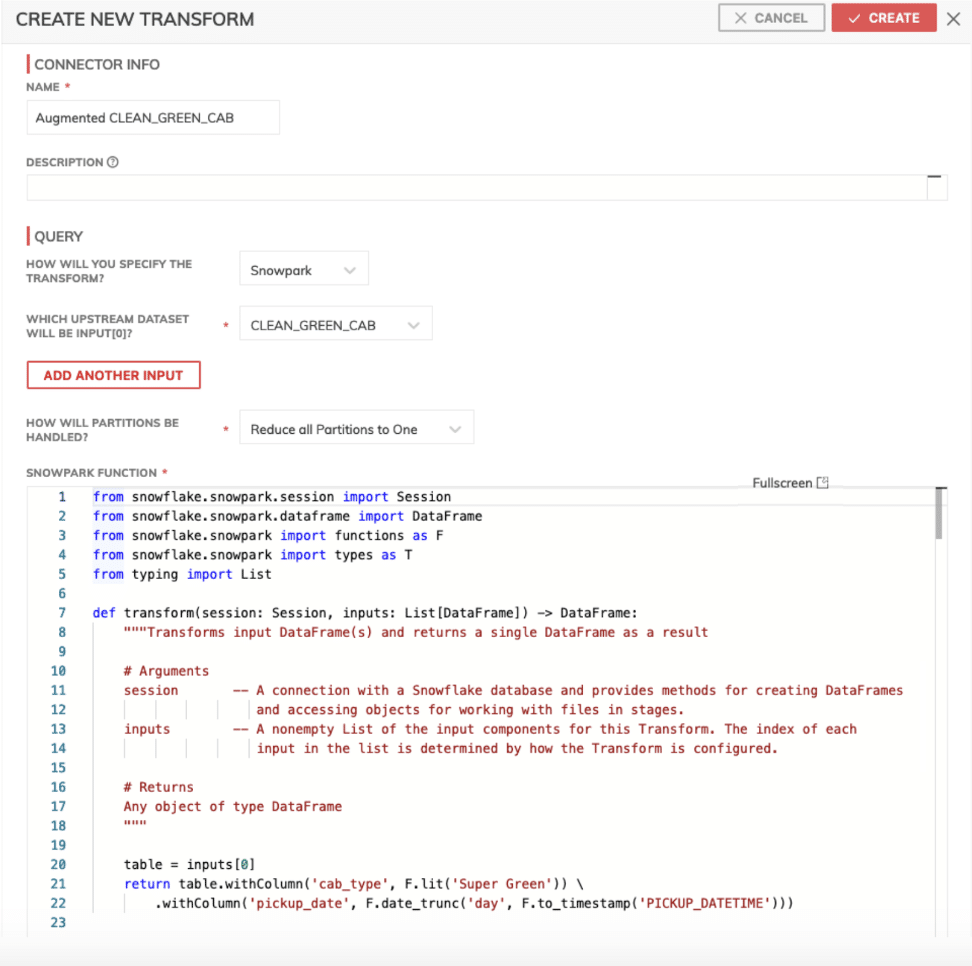
The configuration panel of a Snowpark for Python Transform in the Ascend UI.
Read More: How to Create a Snowpark Pipeline
How to Use Snowflake Snowpark
In this video, Jon Osborn, Field CTO at Ascend, and Josh Weyburne, Sales Engineering Manager at Snowflake show how to use Snowpark and its benefits when building data pipelines.
Embracing Snowflake Snowpark
The tools and platforms we employ become quintessential in defining the efficiency, scalability, and success of our data projects. Snowflake Snowpark, with its pioneering approach, stands as a beacon of innovation in this realm. By integrating robust programming languages directly within Snowflake and synergizing with platforms like Ascend, Snowpark has emerged as more than just a tool — it represents a transformative shift in how we perceive and manage data.
If your goal is to harness the power of your data, Snowflake Snowpark offers an optimized, integrated, and future-ready solution. As businesses continue to evolve, so should our tools, and Snowpark is undoubtedly poised to lead this next wave of data innovation.


