

What Is Data Ingestion?
Why Is Data Ingestion Necessary?
Today, data drives considerable parts of our lives, from crowdsourced recommendations to AI systems identifying fraudulent banking transactions. The same is true for businesses. IDC, a market intelligence firm, predicts the volume of data created each year will top 160 ZB by 2025.

Source: Data Age 2025 Report
Types of Data Ingestion
There are three common types of data ingestion. Deciding which type is appropriate will depend on the kind of data you need to ingest and the frequency at which you need it.
Batch-Based Data Ingestion
Real-Time Data Ingestion
Serverless Architecture-Based Data Ingestion
This solution usually consists of custom software that uses both real-time and batch methods. This is the most complicated form of data ingestion that requires multiple layers of software that manage parts of the ingestion. There is a consistent hand-off between the many layers to ensure data is readily available for review.
It’s important when doing data ingestion to take the approach that optimizes each system’s strengths. For example, queue-based or streaming systems are a requirement for real-time data. However, queues can quickly hit the limits of what they’re designed for if the level of transformation complexity starts to rise beyond what basic tools were built to do.
A better option, in this instance, might be a data orchestration or other data management tool. When it comes to data ingestion, it’s vital to apply the right tool for the right use case.
Data Ingestion vs ETL and ELT Processes
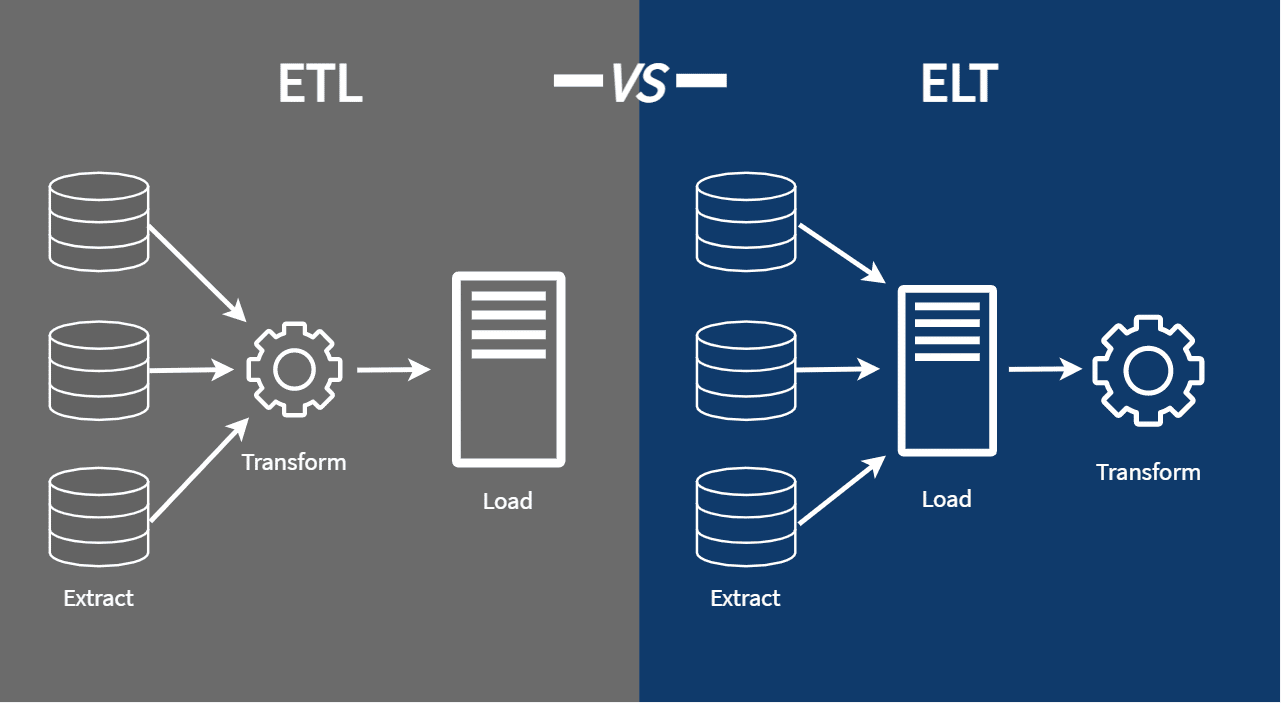
Source: Nicholas Leong
While data ingestion is often understood as the Extract and Load part of ETL and ELT, ingestion is a broader process. Most ETL and ELT processes are focused on transforming data into well-defined structures optimized for analytics.
The focus of data ingestion is gathering data and loading it into a queryable format, with relevant metadata, to prepare it for further downstream transformation and delivery. Ingestion enhances ‘extract and load’ with metadata discovery, automation, and partition management.
Data Ingestion Challenges
Complexity

Performance
Data Security
Connector Rigidity
Four Tips to Get Started
Determine the Level of Data Volatility
Hold Onto More Than You Need
Understand the Business Value
Slow and Steady Wins the Race
Unlocking Data's Potential
In conclusion, the journey of data within an organization begins with the pivotal step of data ingestion. This process, though complex and multifaceted, is the cornerstone for unlocking the latent potential of data. By embracing effective data ingestion strategies, organizations can ensure seamless, secure, and swift assimilation of data from myriad sources.
This enables the synthesis of meaningful insights, empowers informed decision-making, and fosters innovative solutions in an ever-evolving digital landscape. As the tapestry of data continues to expand, understanding and mastering the nuances of data ingestion will remain paramount for data engineers and organizations aiming to remain ahead in the competitive data-driven world.
Read More: Zero ETL: What’s Behind the Hype?


