

Thank you to the hundreds of AWS re:Invent attendees who stopped by our booth! We hope the real-time demonstrations of Ascend automating data pipelines were a real treat—along with the special edition T-Shirt designed specifically for the show (picture of our founder and CEO rocking the t-shirt below). Our official product updates today draw on previews from the show, including a major upgrade to our support for Databricks, and a new lineage visualization graph. Read on!

Improved Support for Databricks
- Increase accessibility, ease of use, and transparency
- Collaborate on data pipelines of any complexity
- Scale support across many more data teams and business units
The demonstration at re:Invent also highlighted the power of Ascend automation from the command line. With this approach, we’re able to augment our uniquely beautiful and intuitive visualization of data pipelines. We focused on showcasing two scenarios during the show. In the first one, with a few lines of code, engineers create, clone, and deploy entire pipelines from scratch in just a few seconds. In the second one, they are able to link two pipelines end-to-end, guaranteeing unbreakable lineage across the two data flows.
To support our Databricks customers, this week our engineering team released an upgrade to our integration to run on the latest Databricks APIs, and added features specifically to ease getting data into the lakehouse:
- Support COPY INTO from staged partitions into Databricks data pipelines;
- Improved performance by tuning page and partition size for Databricks Read Connector.
If you are considering adding Databricks to your capabilities, contact us to evaluate how Ascend automates data pipelines on this data platform!
New Dynamic Visualization of Data Lineage
Ascend’s UI has always contained an auto-generated lineage graph as part of its gorgeous low-code user interface, drawing dependency lines between components based on the transformation logic provided by the user. What’s new is a dedicated Flow Lineage screen in the Observe panel.
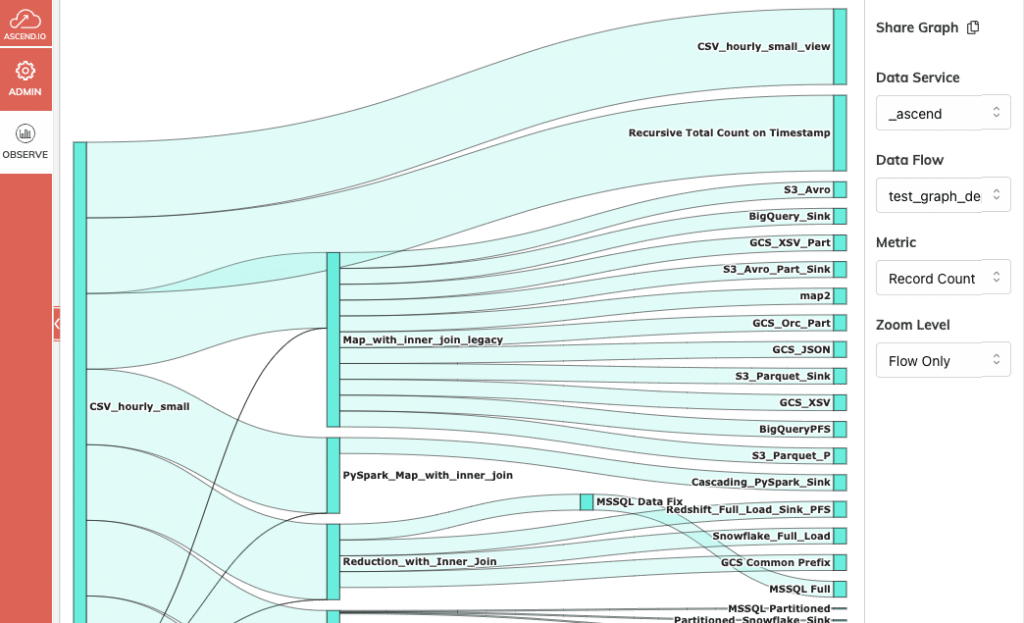
This screen is not a static report that is out of date the moment it is generated. Instead, it is a Sankey diagram driven by the same dynamic metadata that runs the Ascend control plane. The user can interactively click on elements of the diagram to navigate up and down the lineage graph, as well as zoom in and out to include ranges of upstream and downstream nodes. In addition, the metric that determines the width of each “edge” of the graph can be customized. The graph can also be shared as a link with other users.
Check it out and give us feedback, as we continue to improve this powerful new addition to the Ascend Observe capabilities!
Get Data In Your Pipelines!
Pipelines are thirsty for data, and since intelligent pipelines process data incrementally, several of our enhancements these past two weeks solved for incremental ingestion needs from popular data sources—including Marketo, Shopify, Google Analytics 4, and Snowflake.
Other data ingestion enhancements include:
- Incremental read for MS SQL can now be based on a datetime column
- Native data types support in our Salesforce Read Connector and support for the new Hubspot API token.
- Improved performance by upgrading our ingestion engine from Spark 3.2.0 to 3.2.2
- New object aggregation strategy that reshapes object listings based on object metadata, such as last modified time or regex patterns.
- Enabled multi-table Postgres ingestion to accelerate ingestion from this popular source.
- Better customer control over, and logging of, the open-source Spark cluster that powers Ascend ingestion. This will help customers manage the running cost of the Ascend engine in their environments.
- Upgraded Ascend to use the newest BigQuery Write API, eliminating interim staging buckets to get data into BigQuery.


